How to Convert HTML Pages to PDF using Python
Convert HTML to PDF with Python
PDF is one of the most used digital format to save or transfer documents. In this article, we will learn how to convert HTML page to PDF.
What additional libraries or software do we need?
We will use pdfkit library and wkhtmltopdf.
Install pdfkit
To install pdfkit, run the following pip command.
pip install pdfkit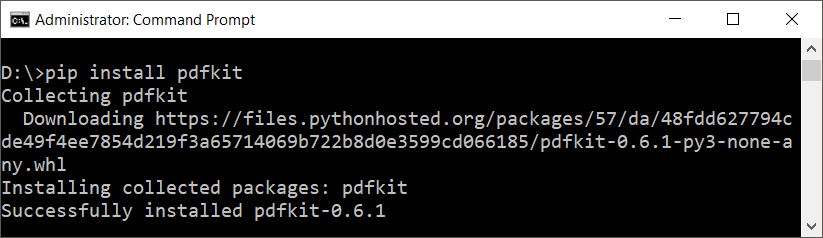
Install wkhtmltopdf
Ubuntu or Debian users can install wkhtmltopdf using below apt-get command.
sudo apt-get install wkhtmltopdfProvide the password if prompted.
Windows users can download wkhtmltopdf from this official github repository wkhtmltopdf. The file size would be around 25MB and takes a moment to download.
Once downloaded, double click on the binary file and continue with the installation. It would be mostly installed at the path C:\Program Files\wkhtmltopdf. We should add bin folder to the system PATH variable in Environment Variables. For example, C:\Program Files\wkhtmltopdf\bin.
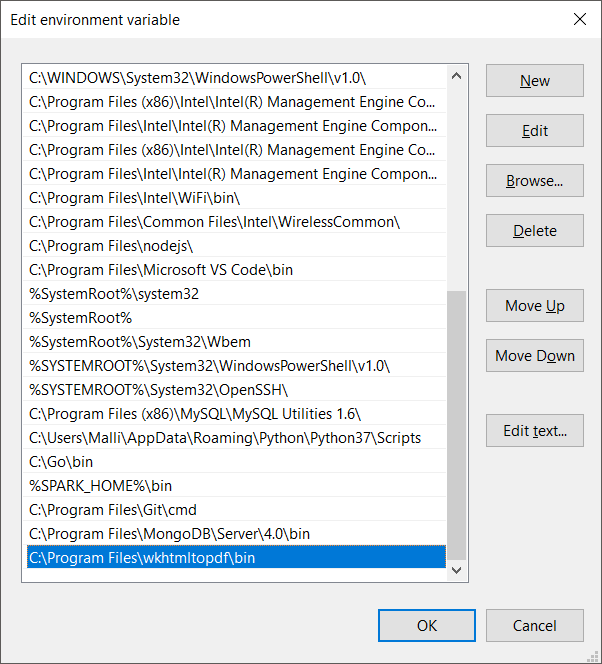
Restart the command prompt, if you are running the python program using command prompt python command for the Path to take effect.
Example 1: HTML to PDF using URL
Now that the environment is setup, following is a simple example to convert HTML to PDF, where HTML is downloaded from a URL. We use the function from_url().
Python Program
import pdfkit
pdfkit.from_url('https://www.google.com/','sample.pdf') The converted PDF file is saved to the current path in the command prompt or terminal.
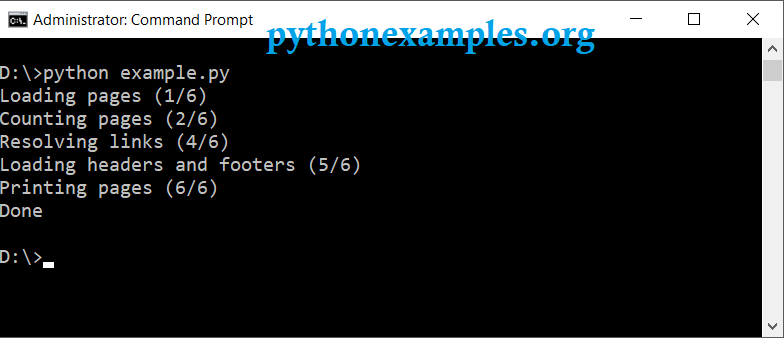
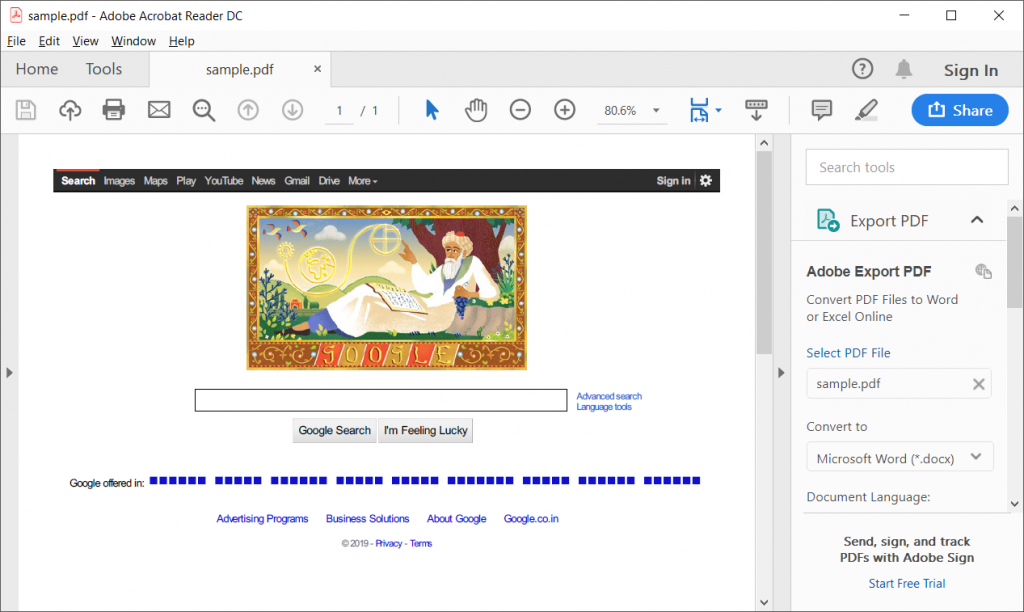
Output pdf file would look like
Example 2: Convert HTML to PDF from Local File
If your HTML file is stored locally, you can use from_file() function and convert the local HTML file to PDF.
Python Program
import pdfkit
pdfkit.from_file('local.html', 'sample.pdf') Example 2: Convert HTML String to PDF
If your HTML data is stored in a Python variable, you can use from_string() function and convert the HTML string to PDF.
Python Program
import pdfkit
var htmlstr = '<h2>Heading 2</h2><p>Sample paragraph.</p>'
pdfkit.from_string(htmlstr, 'sample.pdf') 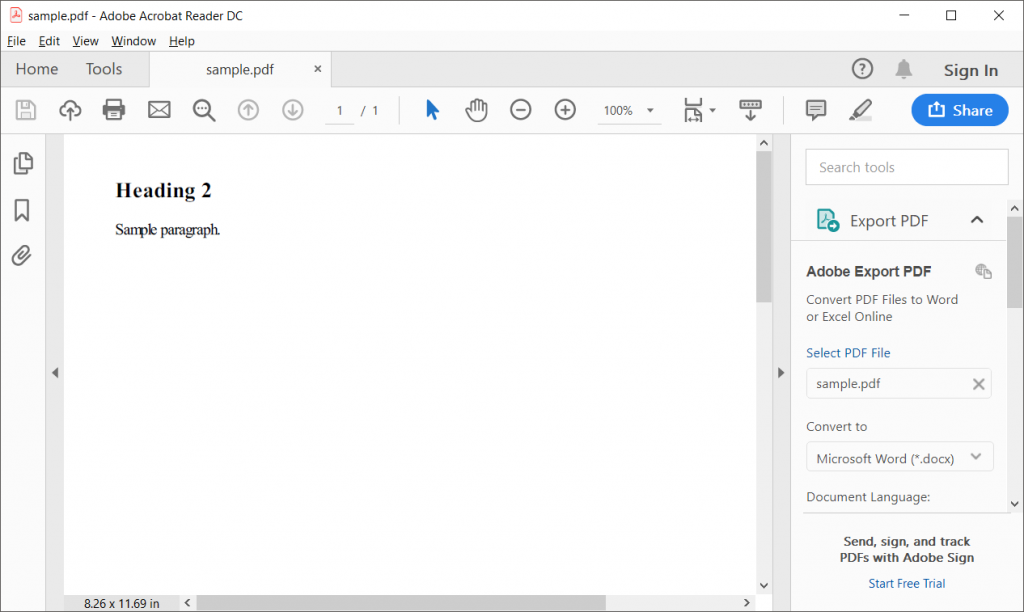
Summary
We have successfully converted a HTML data to PDF. We have considered HTML data to be from a URL, local file or a string.