Pandas DataFrame - Remove duplicates
Pandas DataFrame - Remove duplicates
In Pandas, you can delete duplicate rows based on all columns, or specific columns, using DataFrame drop_duplicates() method.
In this tutorial, we shall go through examples on how to remove duplicate rows in a DataFrame using drop_duplicates() methods.
1. Remove duplicate rows from DataFrame based on all columns using drop_duplicates() method
In this example, we are given a DataFrame in df. We have to remove the duplicate rows from this DataFrame based on values from all the columns. We have to use DataFrame drop_duplicates() method in this example.
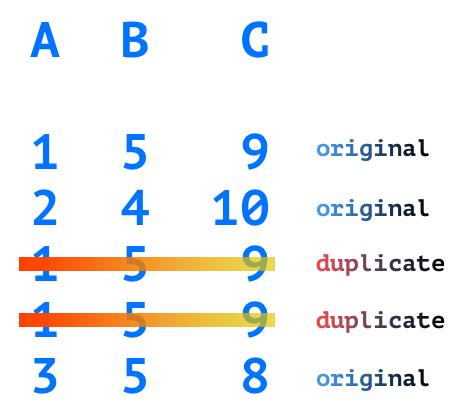
Steps
- Given a DataFrame in df with three columns 'A', 'B', and 'C', and five rows.
df = pd.DataFrame({
'A': [1, 2, 1, 1, 3],
'B': [5, 4, 5, 5, 5],
'C': [9, 10, 9, 9, 8]})- Call drop_duplicates() method on the DataFrame df.
df.drop_duplicates()The method returns a new DataFrame created from the original DataFrame by removing the duplicates. By default, the drop_duplicates() method considers all the columns for searching duplicate content.
- You may store the returned DataFrame in a new variable.
df_no_duplicates = df.drop_duplicates()- You may print the returned DataFrame to output using print() built-in function.
print(df_no_duplicates)Program
The complete program to remove duplicate rows from a given DataFrame df based on the values of all columns.
Python Program
import pandas as pd
# Take a sample DataFrame
df = pd.DataFrame({
'A': [1, 2, 1, 1, 3],
'B': [5, 4, 5, 5, 5],
'C': [9, 10, 9, 9, 8]})
# Remove duplicate rows based on all columns
df_no_duplicates = df.drop_duplicates()
print(f"Original DataFrame\n{df}\n")
print(f"DataFrame with no duplicates\n{df_no_duplicates}")Output
Original DataFrame
A B C
0 1 5 9
1 2 4 10
2 1 5 9
3 1 5 9
4 3 5 8
DataFrame with no duplicates
A B C
0 1 5 9
1 2 4 10
4 3 5 8The row [1 5 9] occurred three times, but only the first occurrence is retained, and the duplicates are removed.
Explanation
Original DataFrame
A B C
0 1 5 9 ← original row
1 2 4 10 ← original row
2 1 5 9 ← duplicate of row at index=0
3 1 5 9 ← duplicate of row at index=0
4 3 5 8 ← original row
Remove the duplicates highlighted, and you will get the
DataFrame with no duplicates
A B C
0 1 5 9
1 2 4 10
4 3 5 82. Remove duplicate rows from DataFrame based on a single column using drop_duplicates() method
In this example, we are given a DataFrame in df. We have to remove the duplicate rows from this DataFrame based on values from the column 'B'. We have to use DataFrame drop_duplicates() method in this example.

Steps
- Given a DataFrame in df with three columns 'A', 'B', and 'C', and five rows.
df = pd.DataFrame({
'A': [1, 2, 1, 1, 3],
'B': [5, 4, 5, 5, 5],
'C': [9, 10, 9, 9, 8]})- Call drop_duplicates() method on the DataFrame df, and pass the list of columns, for subset parameter, based on which we would like to remove the duplicates. Since, we would like to remove the duplicates based on column 'B', pass column 'B' in a list for subset parameter to the drop_duplicates() method.
df.drop_duplicates(subset=['B'])The method returns a new DataFrame created from the original DataFrame by removing the duplicates based on the values of given column. You may store it in a new variable.
df_no_duplicates = df.drop_duplicates(subset=['B'])- You may print the returned DataFrame to output.
print(df_no_duplicates)Program
The complete program to remove duplicate rows from a given DataFrame df based on the values of all columns.
Python Program
import pandas as pd
# Take a sample DataFrame
df = pd.DataFrame({
'A': [1, 2, 1, 1, 3],
'B': [5, 4, 5, 5, 5],
'C': [9, 10, 9, 9, 8]})
# Remove duplicate rows based on column 'B'
df_no_duplicates = df.drop_duplicates(subset=['B'])
print(f"Original DataFrame\n{df}\n")
print(f"DataFrame with no duplicates\n{df_no_duplicates}")Output
Original DataFrame
A B C
0 1 5 9
1 2 4 10
2 1 5 9
3 1 5 9
4 3 5 8
DataFrame with no duplicates
A B C
0 1 5 9
1 2 4 10Explanation
Original DataFrame
A B C
0 1 5 9 ← original row
1 2 4 10 ← original row
2 1 5 9 ← duplicate of 'B' at index=0
3 1 5 9 ← duplicate of 'B' at index=0
4 3 5 8 ← duplicate of 'B' at index=0
Remove the duplicates highlighted, and you will get the
DataFrame with no duplicates
A B C
0 1 5 9
1 2 4 103. Remove duplicate rows from DataFrame based on multiple columns using drop_duplicates() method
This scenario is kind of an extension to the previous example, where we considered only one column to remove duplicates from a DataFrame.
In this example, we have to remove duplicates based on two columns: 'A' and 'B'.

Steps
- Given a DataFrame in df with three columns 'A', 'B', and 'C', and five rows.
df = pd.DataFrame({
'A': [1, 2, 1, 1, 3],
'B': [5, 4, 5, 5, 5],
'C': [9, 10, 9, 9, 8]})- Call drop_duplicates() method on the DataFrame df, and pass the list of columns, for subset parameter, based on which we would like to remove the duplicates. Since, we would like to remove the duplicates based on columns 'A' and 'B', pass these two column labels in a list for subset parameter to the drop_duplicates() method.
df.drop_duplicates(subset=['A', 'B'])The method returns a new DataFrame created from the original DataFrame by removing the duplicates based on the values of given column. You may store it in a new variable.
df_no_duplicates = df.drop_duplicates(subset=['A', 'B'])- You may print the returned DataFrame to output.
print(df_no_duplicates)Program
The complete program to remove duplicate rows from a given DataFrame df based on the values of all columns.
Python Program
import pandas as pd
# Take a sample DataFrame
df = pd.DataFrame({
'A': [1, 2, 1, 1, 3],
'B': [5, 4, 5, 5, 5],
'C': [9, 10, 9, 9, 8]})
# Remove duplicate rows based on all columns
df_no_duplicates = df.drop_duplicates(subset=['A', 'B'])
print(f"Original DataFrame\n{df}\n")
print(f"DataFrame with no duplicates\n{df_no_duplicates}")Output
Original DataFrame
A B C
0 1 5 9
1 2 4 10
2 1 5 9
3 1 5 9
4 3 5 8
DataFrame with no duplicates
A B C
0 1 5 9
1 2 4 10
4 3 5 8Explanation
Original DataFrame
A B C
0 1 5 9 ← original row
1 2 4 10 ← original row
2 1 5 9 ← duplicate of 'B' at index=0
3 1 5 9 ← duplicate of 'B' at index=0
4 3 5 8 ← original row
Remove the duplicates highlighted, and you will get the
DataFrame with no duplicates
A B C
0 1 5 9
1 2 4 10
4 3 5 8Summary
In this Pandas Tutorial, we learned how to remove duplicates from a DataFrame using drop_duplicates() method. We have covered uses cases of removing the duplicate rows based on all columns, a single column, or multiple columns, with example programs.