PostgreSQL GROUP BY Clause
PostgreSQL GROUP BY Clause
The PostgreSQL GROUP BY clause is used to group rows that have the same values in specified columns into aggregated data. This clause is essential for performing aggregate functions like COUNT, SUM, AVG, MAX, and MIN on groups of data.
Syntax
SELECT column1, column2, aggregate_function(column3)
FROM table_name
GROUP BY column1, column2;
The GROUP BY clause has the following components:
column1, column2, ...: The columns to group by.aggregate_function(column3): The aggregate function to apply to each group.
Example PostgreSQL GROUP BY Clause Queries
Let's look at some examples of PostgreSQL GROUP BY clause queries:
1. Basic GROUP BY Example
SELECT department_id, COUNT(*) AS employee_count
FROM employees
GROUP BY department_id;
This query retrieves the department_id and the count of employees in each department from the employees table. It groups the results by department_id.
2. GROUP BY with Multiple Columns
SELECT department_id, job_title, AVG(salary) AS average_salary
FROM employees
GROUP BY department_id, job_title;
This query retrieves the department_id, job_title, and the average salary for each job title in each department from the employees table. It groups the results by department_id and job_title.
3. GROUP BY with HAVING Clause
SELECT department_id, COUNT(*) AS employee_count
FROM employees
GROUP BY department_id
HAVING COUNT(*) > 10;
This query retrieves the department_id and the count of employees in each department where the number of employees is greater than 10. It groups the results by department_id and filters the groups using the HAVING clause.
4. GROUP BY with ORDER BY Clause
SELECT department_id, SUM(salary) AS total_salary
FROM employees
GROUP BY department_id
ORDER BY total_salary DESC;
This query retrieves the department_id and the total salary for each department from the employees table. It groups the results by department_id and sorts the results by total_salary in descending order.
Full Example
Let's go through a complete example that includes creating a table, inserting data, and using the GROUP BY clause to group data.
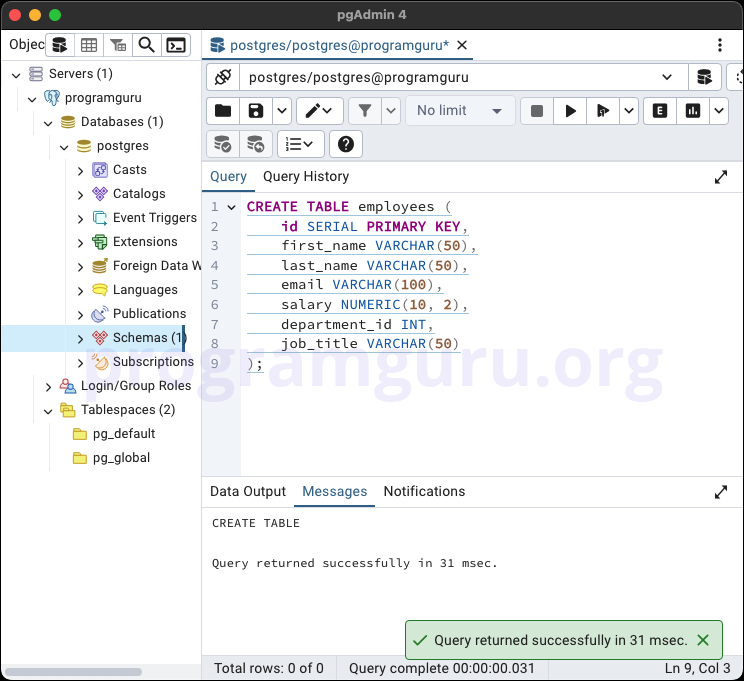
Step 1: Creating a Table
This step involves creating a new table named employees to store employee data.
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
salary NUMERIC(10, 2),
department_id INT,
job_title VARCHAR(50)
);
In this example, we create a table named employees with columns for id, first_name, last_name, email, salary, department_id, and job_title.
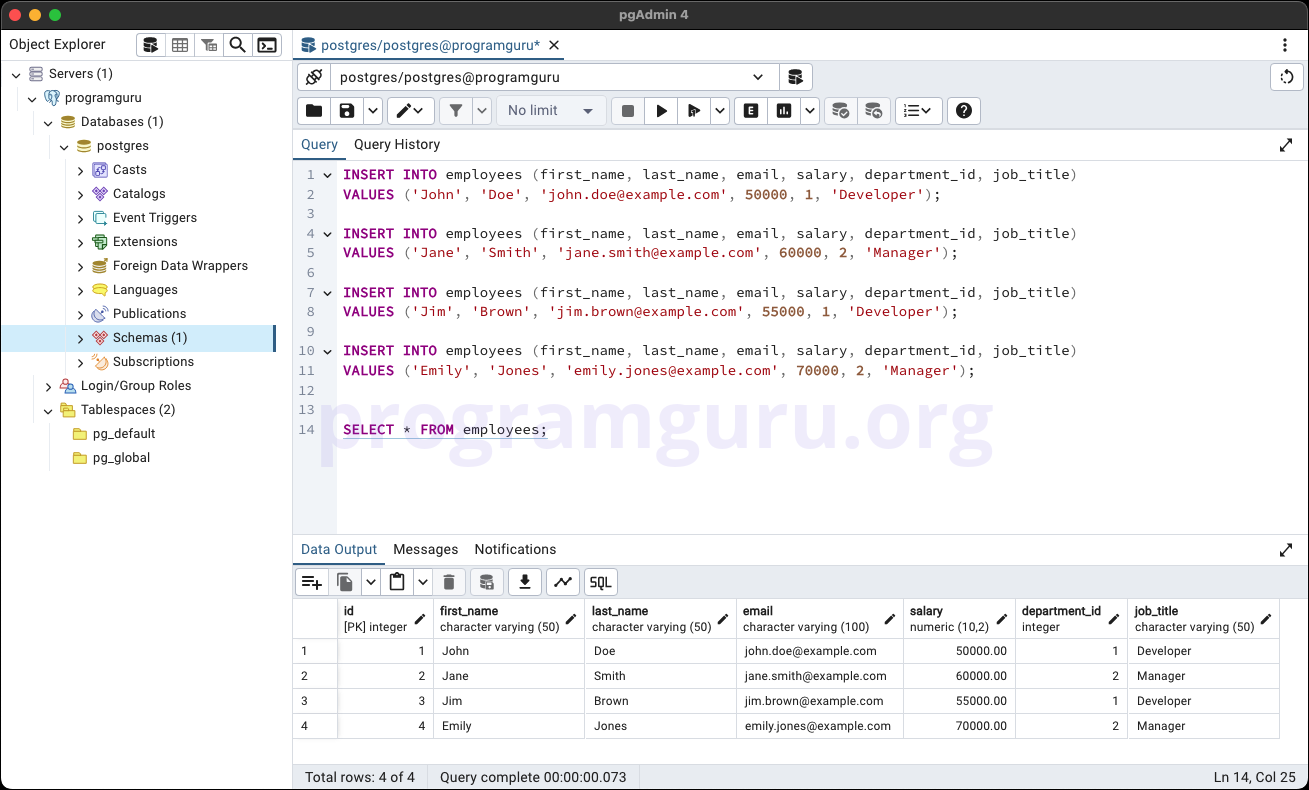
Step 2: Inserting Data into the Table
This step involves inserting some sample data into the employees table.
INSERT INTO employees (first_name, last_name, email, salary, department_id, job_title)
VALUES ('John', 'Doe', 'john.doe@example.com', 50000, 1, 'Developer');
INSERT INTO employees (first_name, last_name, email, salary, department_id, job_title)
VALUES ('Jane', 'Smith', 'jane.smith@example.com', 60000, 2, 'Manager');
INSERT INTO employees (first_name, last_name, email, salary, department_id, job_title)
VALUES ('Jim', 'Brown', 'jim.brown@example.com', 55000, 1, 'Developer');
INSERT INTO employees (first_name, last_name, email, salary, department_id, job_title)
VALUES ('Emily', 'Jones', 'emily.jones@example.com', 70000, 2, 'Manager');
Here, we insert data into the employees table.
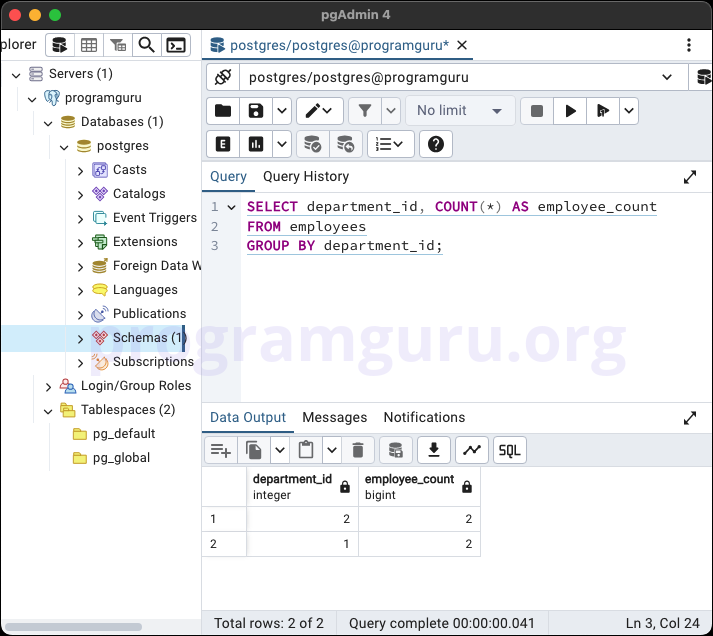
Step 3: Grouping Data with GROUP BY
This step involves using the GROUP BY clause to group data in the employees table.
Basic GROUP BY
SELECT department_id, COUNT(*) AS employee_count
FROM employees
GROUP BY department_id;
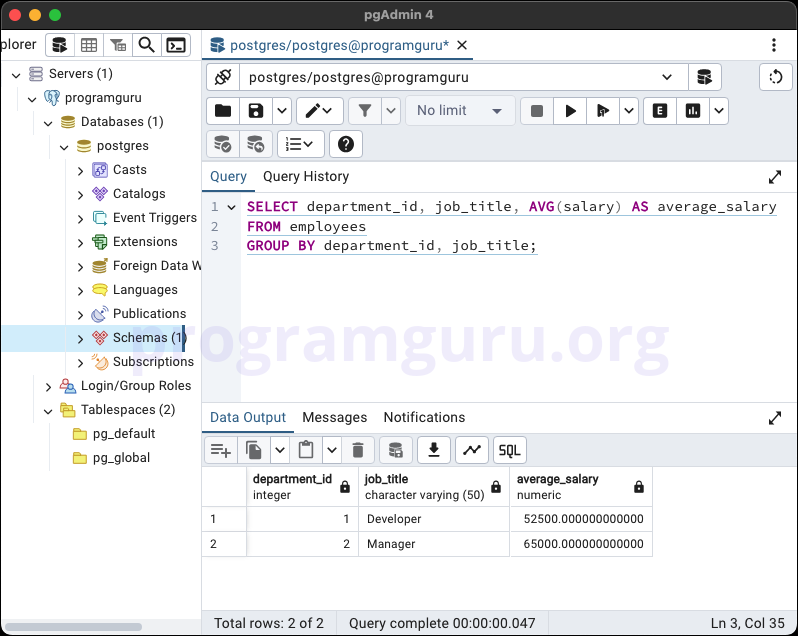
GROUP BY with Multiple Columns
SELECT department_id, job_title, AVG(salary) AS average_salary
FROM employees
GROUP BY department_id, job_title;
GROUP BY with HAVING Clause
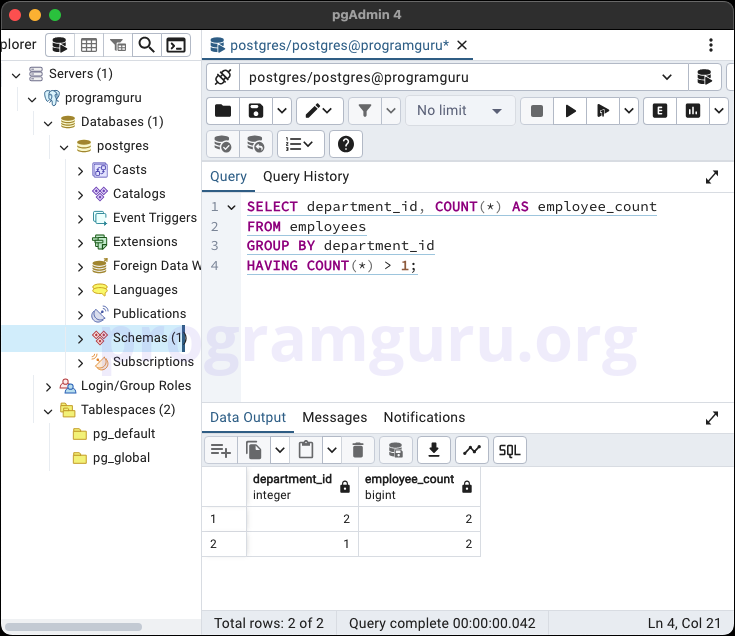
SELECT department_id, COUNT(*) AS employee_count
FROM employees
GROUP BY department_id
HAVING COUNT(*) > 1;
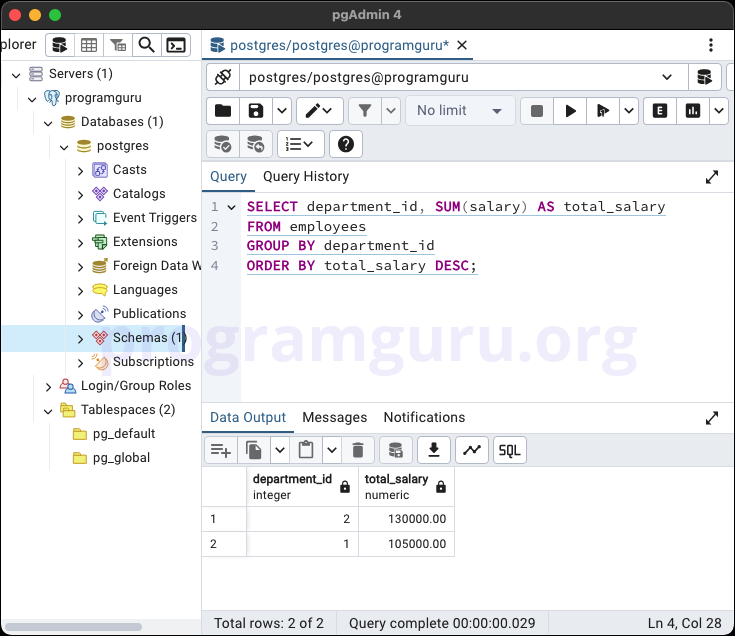
GROUP BY with ORDER BY Clause
SELECT department_id, SUM(salary) AS total_salary
FROM employees
GROUP BY department_id
ORDER BY total_salary DESC;
These queries demonstrate how to use the GROUP BY clause to group data in the employees table, including grouping by single and multiple columns, using the HAVING clause to filter groups, and sorting grouped results with the ORDER BY clause.
Conclusion
The PostgreSQL GROUP BY clause is a fundamental tool for grouping rows and performing aggregate functions on groups of data. Understanding how to use the GROUP BY clause and its syntax is essential for effective data analysis and reporting in PostgreSQL databases.